[.Net] Fast sending data from database to Kafka
In this article I will show the fast way to read data from database and sent to Kafka topic without storing in memory.
The fastest way would be use the Stream Processors in Kafka, but for this moment (January 2024) there is no support Stream Processors in Kafka for .NET.
All code examples you can find here.
First thing you have to do is create new database and source table in SQL Server. To do it please execute script in Sql Management Studio.
USE [master]
GO
CREATE DATABASE [Kafka]
CONTAINMENT = NONE
ON PRIMARY
( NAME = N'Kafka', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL15.SQLEXPRESS\MSSQL\DATA\Kafka.mdf' , SIZE = 8192KB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB )
LOG ON
( NAME = N'Kafka_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL15.SQLEXPRESS\MSSQL\DATA\Kafka_log.ldf' , SIZE = 8192KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB )
WITH CATALOG_COLLATION = DATABASE_DEFAULT
GO
ALTER DATABASE [Kafka] SET COMPATIBILITY_LEVEL = 150
GO
IF (1 = FULLTEXTSERVICEPROPERTY('IsFullTextInstalled'))
begin
EXEC [Kafka].[dbo].[sp_fulltext_database] @action = 'enable'
end
GO
ALTER DATABASE [Kafka] SET ANSI_NULL_DEFAULT OFF
GO
ALTER DATABASE [Kafka] SET ANSI_NULLS OFF
GO
ALTER DATABASE [Kafka] SET ANSI_PADDING OFF
GO
ALTER DATABASE [Kafka] SET ANSI_WARNINGS OFF
GO
ALTER DATABASE [Kafka] SET ARITHABORT OFF
GO
ALTER DATABASE [Kafka] SET AUTO_CLOSE OFF
GO
ALTER DATABASE [Kafka] SET AUTO_SHRINK OFF
GO
ALTER DATABASE [Kafka] SET AUTO_UPDATE_STATISTICS ON
GO
ALTER DATABASE [Kafka] SET CURSOR_CLOSE_ON_COMMIT OFF
GO
ALTER DATABASE [Kafka] SET CURSOR_DEFAULT GLOBAL
GO
ALTER DATABASE [Kafka] SET CONCAT_NULL_YIELDS_NULL OFF
GO
ALTER DATABASE [Kafka] SET NUMERIC_ROUNDABORT OFF
GO
ALTER DATABASE [Kafka] SET QUOTED_IDENTIFIER OFF
GO
ALTER DATABASE [Kafka] SET RECURSIVE_TRIGGERS OFF
GO
ALTER DATABASE [Kafka] SET DISABLE_BROKER
GO
ALTER DATABASE [Kafka] SET AUTO_UPDATE_STATISTICS_ASYNC OFF
GO
ALTER DATABASE [Kafka] SET DATE_CORRELATION_OPTIMIZATION OFF
GO
ALTER DATABASE [Kafka] SET TRUSTWORTHY OFF
GO
ALTER DATABASE [Kafka] SET ALLOW_SNAPSHOT_ISOLATION OFF
GO
ALTER DATABASE [Kafka] SET PARAMETERIZATION SIMPLE
GO
ALTER DATABASE [Kafka] SET READ_COMMITTED_SNAPSHOT OFF
GO
ALTER DATABASE [Kafka] SET HONOR_BROKER_PRIORITY OFF
GO
ALTER DATABASE [Kafka] SET RECOVERY SIMPLE
GO
ALTER DATABASE [Kafka] SET MULTI_USER
GO
ALTER DATABASE [Kafka] SET PAGE_VERIFY CHECKSUM
GO
ALTER DATABASE [Kafka] SET DB_CHAINING OFF
GO
ALTER DATABASE [Kafka] SET FILESTREAM( NON_TRANSACTED_ACCESS = OFF )
GO
ALTER DATABASE [Kafka] SET TARGET_RECOVERY_TIME = 60 SECONDS
GO
ALTER DATABASE [Kafka] SET DELAYED_DURABILITY = DISABLED
GO
ALTER DATABASE [Kafka] SET ACCELERATED_DATABASE_RECOVERY = OFF
GO
ALTER DATABASE [Kafka] SET QUERY_STORE = OFF
GO
USE [Kafka]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[KafkaMessages](
[Id] [int] IDENTITY(1,1) NOT NULL,
[Message] [nvarchar](max) NOT NULL,
CONSTRAINT [PK_KafkaMessages] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
SET IDENTITY_INSERT [dbo].[KafkaMessages] ON
GO
INSERT [dbo].[KafkaMessages] ([Id], [Message]) VALUES (1, N'1')
GO
INSERT [dbo].[KafkaMessages] ([Id], [Message]) VALUES (2, N'2')
GO
INSERT [dbo].[KafkaMessages] ([Id], [Message]) VALUES (3, N'3')
GO
INSERT [dbo].[KafkaMessages] ([Id], [Message]) VALUES (4, N'4')
GO
INSERT [dbo].[KafkaMessages] ([Id], [Message]) VALUES (5, N'5')
GO
INSERT [dbo].[KafkaMessages] ([Id], [Message]) VALUES (6, N'6')
GO
INSERT [dbo].[KafkaMessages] ([Id], [Message]) VALUES (7, N'7')
GO
INSERT [dbo].[KafkaMessages] ([Id], [Message]) VALUES (8, N'8')
GO
INSERT [dbo].[KafkaMessages] ([Id], [Message]) VALUES (9, N'9')
GO
INSERT [dbo].[KafkaMessages] ([Id], [Message]) VALUES (10, N'10')
GO
SET IDENTITY_INSERT [dbo].[KafkaMessages] OFF
GO
USE [master]
GO
ALTER DATABASE [Kafka] SET READ_WRITE
GOWhen you have your database we can install required nugget packages:
– Confluent.Kafka
– Dapper
– System.Data.SqlClient
Now you can start our Kafka with zookeeper using docker-compose. You can find here, how to start docker-compose and offset explorer .
First thing you will code, is fast reading data from Kafka without data buffering using Dapper. To do it we will create new Database Repository.
using Dapper;
using System.Data.SqlClient;
namespace KafkaDatabaseProducer
{
internal class DatabaseRepository
{
public async IAsyncEnumerable<DatabaseMessage> GetMessages()
{
var query = "SELECT [Message] FROM [Kafka].[dbo].[KafkaMessages]";
var connectionString = "Server=Win10\\SQLEXPRESS;Database=Kafka;User=sa;Password=Password!";
using var connection = new SqlConnection(connectionString);
using var reader = await connection.ExecuteReaderAsync(query);
var rowParser = reader.GetRowParser<DatabaseMessage>();
while (await reader.ReadAsync())
{
////yield to avoid store data in memory
yield return rowParser(reader);
}
}
}
internal class DatabaseMessage
{
public string Message { get; set; }
}
}The second thing to do, is to create Kafka Producer for sending messages from database. So let’s create your Kafka producer.
Important thing to do is to not await for delivery result, but check them all on sending finish!
using Confluent.Kafka;
namespace KafkaDatabaseProducer
{
internal class KafkaProducer : IDisposable
{
IProducer<Null, string> _producer;
ICollection<Task<DeliveryResult<Null, string>>> _deliveryResults = new List<Task<DeliveryResult<Null, string>>>();
public KafkaProducer()
{
var config = new ProducerConfig { BootstrapServers = "localhost:29092" };
IProducer<Null, string> _producer = new ProducerBuilder<Null, string>(config).Build();
}
public void SendMessage(string message)
{
var task = _producer.ProduceAsync("Test", new Message<Null, string> { Value = message });
_deliveryResults.Add(task);
}
public async Task CheckSending()
{
var results = await Task.WhenAll(_deliveryResults);
if (results.Any(x => x.Status != PersistenceStatus.Persisted))
{
Console.WriteLine("Some messages has been not delivered!");
}
}
public void Dispose()
{
_producer.Dispose();
}
}
}Now you can write main logic of application.
using KafkaDatabaseProducer;
internal class Program
{
public static async Task Main(string[] args)
{
DatabaseRepository databaseRepository = new DatabaseRepository();
KafkaProducer kafkaProducer = new KafkaProducer();
await foreach (var data in databaseRepository.GetMessages())
{
kafkaProducer.SendMessage(data.Message);
}
await kafkaProducer.CheckSending();
Console.ReadKey();
}
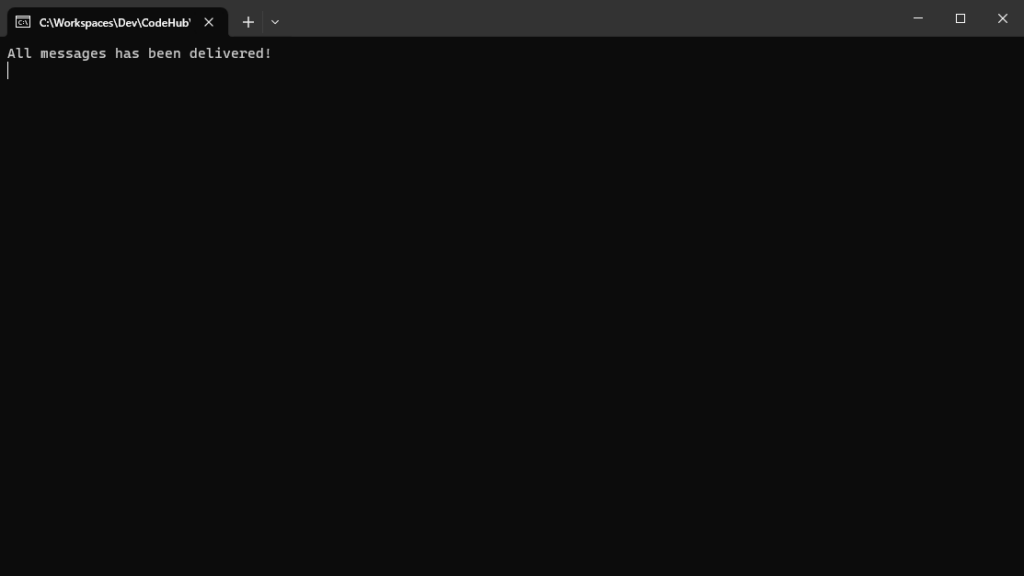
}After run the application, you can see something like this.
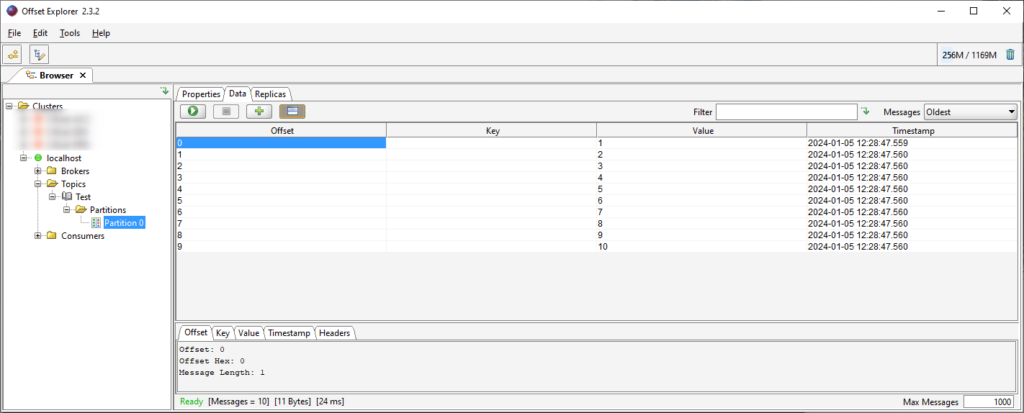
You can also check if your messages has been correctly persisted on Kafka.
Happy coding!
Great solution which provides very fast data sending !
Thanks!